Gesture Detection Using Tensorflow.js
I started this project to create an end-to-end training tool for gesture recognition using deep learning. You can view the code here and try the demo here.
The idea came from some of my work with the Ink & Switch lab. Our team was building a tablet application geared towards creators and found there were many unique challenges, one of which is the lack of input options.
Tablet devices lack input expressiveness and speed compared to a desktop computer. The basic building blocks of all mobile inputs are tap, double tap, and swipe. During one of our design sessions, our team lead suggested the idea of using "magic runes" or "advanced gestures" as user inputs. If a user could draw geometric shapes to trigger certain actions, it would allow for more expressive inputs and controls without taking up valuable screen real estate. Instead of tapping a "delete" button, you might draw an "X" to delete an object. To navigate between windows, draw an arrow in some direction or draw a star to bookmark a note.
The Prototype
As a starting point, you can approximate gesture detection as a similar problem to handwriting recognition. Fortunately, handwriting recognition is almost the "Hello World" of machine learning tutorials so I was able to use those tutorials as a blueprint.
The first step was to collect data. The MNIST handwriting data set commonly used in deep learning tutorials has 70,000 examples, so I assumed I'd need at least on the order of 1,000's to build a proof-of-concept. I started by building a simple React app with a canvas element that allows you to draw gestures using touch input and stored recorded gestures on Airtable.
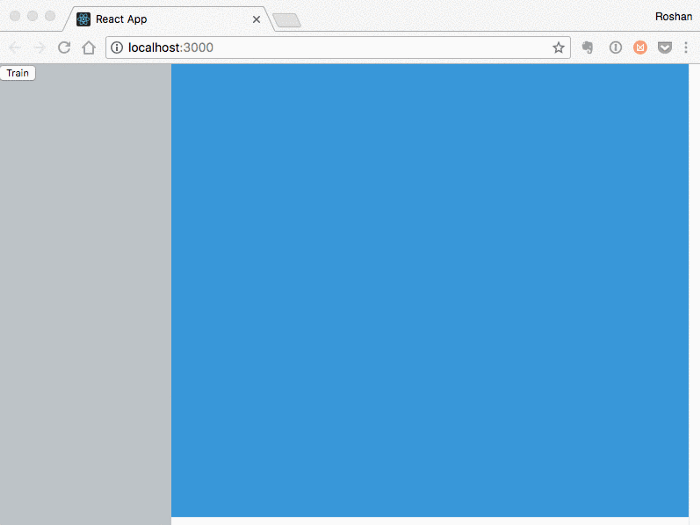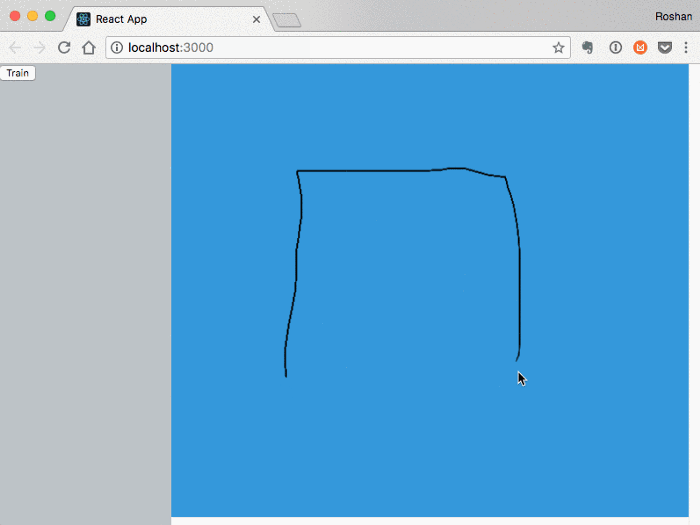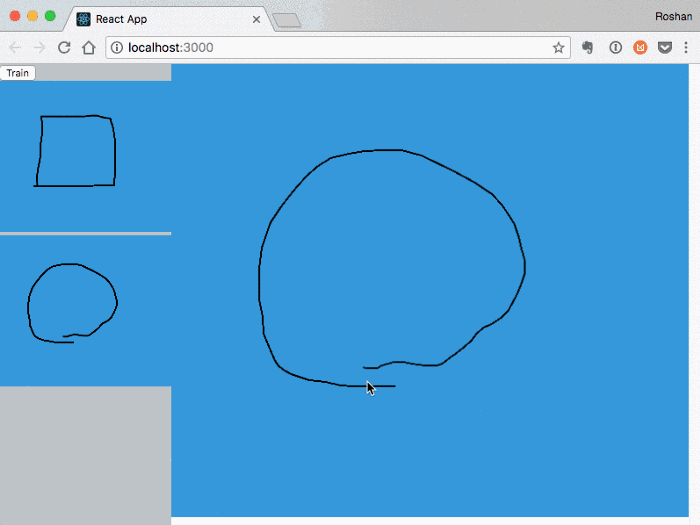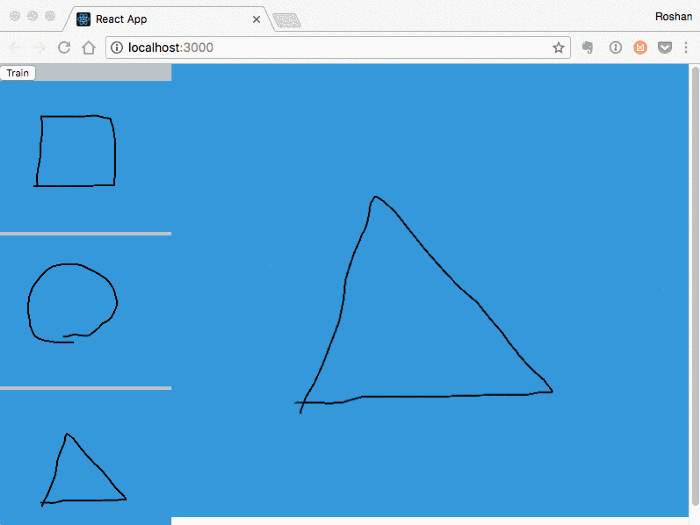
After manually generating a couple hundred gesture examples*, I started on the detector. TensorFlow is one of the most popular libraries for building neural networks, and they conveniently have a client-side TensorFlowjs library. I copied the Convolutional Neural Network (CNN) architecture they use in their MNIST recognizer tutorial as a starting point, so the brunt of the work was now preprocessing the gestures to an input type that the neural net could understand. The MNIST model expects a 28x28 single-channel (i.e. grayscale) pixel input, so we have to scale the gesture down to that size.
Debugging the Gesture Detector
Having plugged it all together, I trained the model on the samples I had generated and the results were… disappointing. I was getting 10–20% accuracy, and creating more samples wasn't improving the model at all. The preprocessing code was my initial suspect, so I wrote a Bitmap component in React to inspect what the neural net was “seeing” right after preprocessing. Here's what the neural network was receiving as inputs compared to the original gesture:
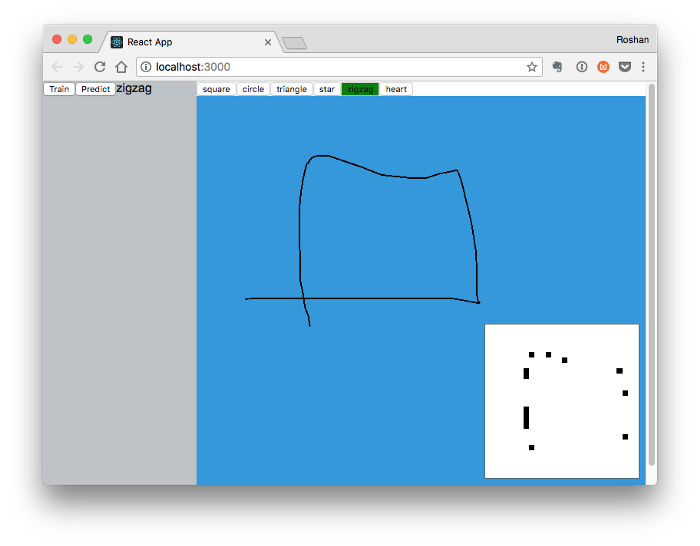
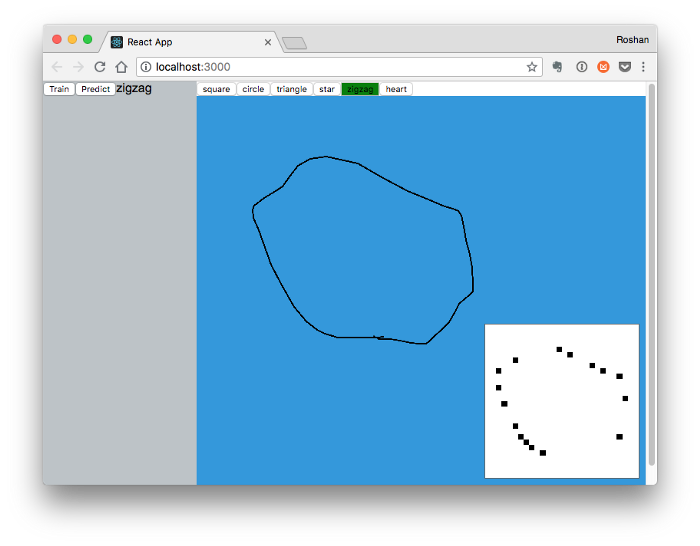
The gestures are losing most of their information during preprocessing and look like a random scattering of pixels. I traced down the issue to the canvas web API, the scale transform was losing most of the relevant path information. There might be more elegant ways of scaling down the gesture without losing the important information, but I found that just increasing the stroke width of the gestures worked for my purposes. The CNN model immediately improved in accuracy, jumping up to ~70%. To make sure I wasn't just overfitting to the training data, I started to shuffle the data and split it into train/test sets before training.
Conclusions
After fixing the preprocessing, my model started to work as expected and improved in accuracy with more data samples. I was surprised to find that it performed with > 90% accuracy after just a few hundred examples, and reached > 95% after about 500 examples across a set of six different gestures. It was convenient to have the entire pipeline from data collection, training, and live testing built in one client-side JS app: as I found examples that confused the detector, I could just create a few dozen more of those examples, and add them to the training data.
My model seems to perform on par with the $1 Recognizer written by researchers at Microsoft and the University of Washington. The $1 Recognizer constructs a "geometric template" from each gesture and feeds those features into a nearest-neighbor algorithm for classification. The comparison is illustrative of the pros and cons of deep learning: the $1 Recognizer requires some specialized knowledge of geometry to pull out the relevant features of a shape and classify them, but the deep learning model can figure out those features directly from bitmaps of gestures. The downside of the deep learning model is that it requires thousands of training samples, whereas the $1 Recognizer only requires a handful of samples per shape.
But the main benefit of deep learning might be its accessibility to software engineers with no specialized training. I doubt I would be able to re-implement the $1 Recognizer, it requires a lot of prerequisite math and geometry that would have been too high of a barrier for me. The CNN does require significantly more training data, but it was conceptually simpler for a software engineer like myself to implement. I'm excited to follow the branch of deep learning where you can automatically learn and optimize neural network architectures and parameters**. It would be a very powerful tool if one day we're able to plug in a neural net in places that previously required a handcrafted algorithm.
Footnotes
* I used a mouse instead of touch to draw gestures and created all of them myself instead of sampling from various people. The detector could be improved by using touch inputs and getting samples from more users.
** https://autokeras.com/